GGUF和Q4_K_M到底是什么?本地大模型量化格式科普
原文来源:微信公众号「泰德瑞的AI生活」
在本地大模型部署中,我们经常会遇到.gguf后缀的文件,以及Q4_K_M这样的量化标识。这些看似简单的字母和数字背后,其实隐藏着三位开源贡献者的名字和一套精心设计的量化方案。
GGUF 的由来
起源:llama.cpp 和 GGML

2022-2023 年,程序员 Georgi Gerganov 开发了 llama.cpp,让普通电脑甚至手机也能跑 Meta 的 Llama 模型。他开发了底层库 GGML(Georgi Gerganov Machine Learning),同时用这个库来存储模型,形成了一种文件格式。
问题出现
随着 GGML 支持的模型越来越多(Llama、Mistral、Qwen、Gemma 等),不同版本不兼容、元数据要单独存文件、加新功能容易出问题——GGML 变得很乱。
GGUF 诞生
2023 年 8 月,llama.cpp 团队彻底升级,把 Machine Learning 改成了 Unified Format,诞生了 GGUF。既致敬 Georgi Gerganov,又代表了统一格式的愿望。
GGUF = Georgi Gerganov Unified Format(.gguf 后缀)
Q4_K_M 是什么
Q = 量化(Quantization)
早期大模型用 FP16(16 位浮点数)或 FP32 存参数,一个 7B 模型就要 10+GB 内存。量化就是把高精度的小数"压扁"成低位数(4 位、5 位),大幅降低显存占用,同时接受一定程度的精度损失。
K = Kawrakow
llama.cpp 核心贡献者 Iwan Kawrakow 引入了全新的量化方法(PR #1684),用更精细的"超级块(superblock)"结构:
- 把权重分成大组(superblock,通常 256 个权重)
- 再把大组分成小块(block,通常 32 或 16 个权重)
- 对每层单独计算缩放因子和偏移
- 把缩放因子也压成低位数(6 位、8 位)
进一步节省空间,同时保留更好精度。K 就是 Kawrakow 姓氏首字母的纪念。
4 = 位数
Q4 = 主要用 4 位(4bits),对应 FP16 的 16 位。以此类推:Q3 = 3 位,Q5 = 5 位。
M = 大小档位
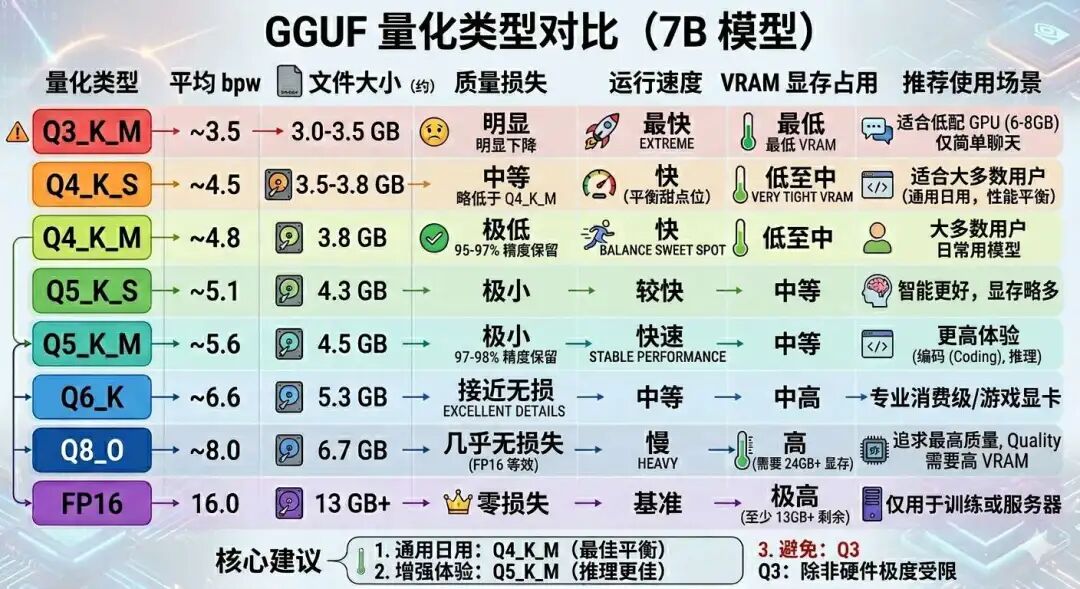
| 档位 | 含义 | 说明 |
|---|---|---|
| S | 最激进压缩 | 几乎所有参数用最低位数,文件最小,但模型会笨一点 |
| M | 常用平衡版(推荐) | 重要层/张量稍微提高精度,其他保持主要位数,质量明显更好,文件只大一点点 |
| L | 更保守 | 更多重要部分用更高精度,质量更好,但文件更大、占用更多显存 |
为什么 Q4_K_M 最受欢迎
Q4_K_M 在"省显存"和"模型不笨"之间找到了最好的平衡。它把模型里比较重要的层/张量稍微提高精度,其他部分保持 4 位,质量明显更好,文件只大一点点。
总结
- G = Georgi Gerganov(llama.cpp 创始人)
- GUF = Unified Format(统一格式)
- Q = Quantization(量化)
- 4 = 4 位精度
- K = Kawrakow(量化方法贡献者)
- M = Medium(中等大小档位)
下次看到 Q4_K_M,你就知道这串字母背后是三位开源贡献者的名字和一套精心设计的量化方案。
相关阅读: