一张5090,上下文直接翻倍!Qwen3.5-27B被「压」到81920 context
作者:荣叔说事 发布日期:2026-03-30
📖 目录
导读
开发者0xSero借了一张RTX 5090跑了几个小时,用TurboQuant把Qwen3.5-27B的可用上下文从44688直接拉到81920——接近翻倍。更疯狂的是,社区已经有人在3090上把同一个模型推到了30万token。本地长上下文的瓶颈,正在被一群工程师用KV cache压缩技术暴力撕开。
核心突破

「我自己也不敢百分百打包票」
3月26日,一个叫0xSero的开发者在X上发了一条帖子。没有长篇大论,没有营销话术,就几行字:
"Got a 5090 for a few hours, got: Qwen3.5-27B-AWQ-4bit with 81920 context up from a max of around 44688~ with vllm"
「我借到一张5090,跑了几个小时。Qwen3.5-27B-AWQ-4bit的上下文从vLLM原来大约44688,拉到了81920。」
然后他补了一句让这条帖子气质完全不同的话:
"I don't trust any of these numbers 100% so people poke around if u can test this out"
「这些数字我自己也不敢百分百打包票,大家如果有条件可以继续去复测。」

关键数据对比
| 配置 | 最大上下文 | 提升倍数 |
|---|---|---|
| baseline(无优化) | 44,688 | - |
| TurboQuant | 81,920 | 1.83倍 |
就这么一条帖子,炸开了本地大模型圈。不是因为81920这个数字有多大——说实话,Qwen3.5-27B官方原生支持262144 token上下文,81920只是它理论上限的三分之一。
真正炸的是:这是在一张消费级显卡上,单卡,没有服务器集群,没有H100,就一张你花2000美元能买到的RTX 5090。
而让这一切成为可能的,是一个叫TurboQuant的KV cache压缩方案。
问题根源
不是模型装不下,是上下文「撑爆了」
很多人对本地跑大模型有一个根深蒂固的误解:觉得OOM(显存不足)是因为模型太大。不完全对。
显存占用分析:
| 项目 | 占用 |
|---|---|
| Qwen3.5-27B AWQ 4bit 模型权重 | 13-16GB |
| RTX 5090 显存 | 32GB |
装是装得下的。真正吃显存的大头,是推理过程中不断膨胀的KV cache。
简单来说:模型每处理一个token,就需要在显存里缓存一组Key和Value向量,供后续生成时做注意力计算。上下文越长,这个缓存越大。
到了4万多token,5090的32GB就扛不住了——模型权重+KV cache加在一起,直接爆显存。
0xSero自己在回复里确认了这个基线:
"on a 5090 with no tricks (vllm inference) i get 44k context before OOM in bf16"
「在5090上,不加任何技巧,纯vLLM推理,bf16精度,大概44K就OOM了。」
所以问题很清楚:模型本身不是瓶颈,KV cache才是。
而TurboQuant要做的,就是把这个最贵的缓存结构,狠狠压一刀。
TurboQuant技术原理
TurboQuant最初来自Google Research的一篇ICLR 2026论文(arXiv: 2504.19874),全称叫TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate。
听名字就知道,这不是那种「把float16改成int4然后祈祷质量别崩太多」的粗暴量化。
核心思路:
- 用随机正交旋转把信息均匀分散到各维度
- 再用坐标级量化逼近近似最优的失真率
- 还额外处理了内积估计误差——这对注意力计算的精度至关重要
论文核心结论:
| 每通道比特数 | 效果 |
|---|---|
| 3.5 bits | absolute quality neutrality(绝对质量中性) |
| 2.5 bits | 边际退化 |
翻译成人话:压得更狠,质量可以几乎不掉。
实测数据
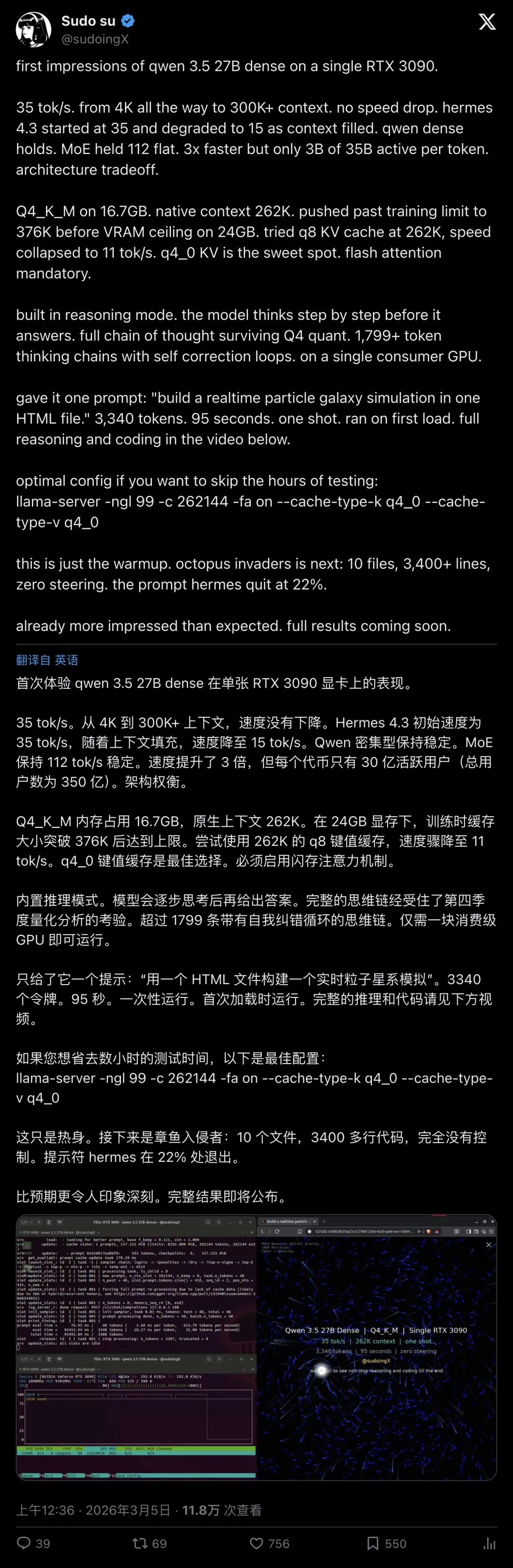
0xSero把这篇论文落地成了一个可以直接跑的vLLM插件。他的GitHub仓库turboquant里,benchmark写得很直白:
测试配置:
| 参数 | 值 |
|---|---|
| 硬件 | 4x RTX 3090 |
| 模型 | Qwen3.5-27B |
| 精度 | bf16 |
| 引擎 | vLLM |
性能对比:
| 指标 | 压缩前 | 压缩后 | 提升 |
|---|---|---|---|
| 最大token容量 | 457,072 | 914,144 | 2.0倍 |
| bytes/token | ~512 | ~198 | 2.6倍压缩 |
而且他在README里写得清清楚楚:Qwen3.5-27B的64层...
社区验证

这个帖子炸开后,社区里立马有人开始复测。
有人在3090上把同一个模型推到了30万token——比官方的26万上限还高。这说明什么?KV cache压缩的潜力可能比论文里说的还要大。
但更重要的是:这是一个开源方案,任何人都可以拿去测,拿去改,拿去在自己的硬件上复现。
总结
关键要点
| 要点 | 说明 |
|---|---|
| 突破 | RTX 5090 上 Qwen3.5-27B 上下文从 44K → 81K |
| 技术 | TurboQuant KV cache 压缩 |
| 压缩比 | ~2.6倍,质量几乎不掉 |
| 开源 | GitHub: turboquant |
| 社区 | 已有人在3090上推到30万token |
技术趋势
本地长上下文的瓶颈,正在被一群工程师用KV cache压缩技术暴力撕开。这不是魔法,是数学。
TurboQuant的核心贡献:
- 把KV cache压缩到接近理论最优
- 保持模型质量几乎不变
- 让消费级显卡能跑更长的上下文
🔗 相关链接
- 论文:arXiv: 2504.19874
- GitHub:turboquant
- 原帖:0xSero X/Twitter
📘 本文来自微信公众号「荣叔说事」,由 AiTimes 智能时代整理发布
AiTimes 智能时代 © 2026