RTX 5070 Ti 跑通 Qwen3.6-35B-A3B:消费级显卡的极限被彻底打破
本文来源: 微信公众号原文
版权声明: 本文转载自微信公众号,版权归原作者所有。仅供学习交流,如有侵权请联系删除。
概述
消费级显卡的极限,被彻底打破了。
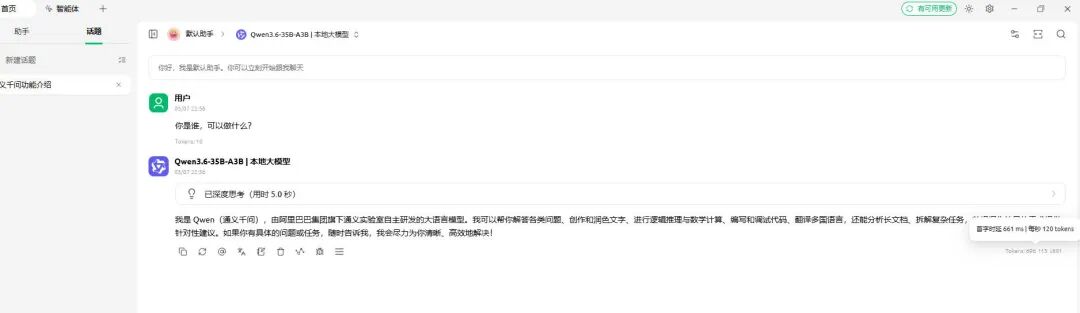
就在最近,有人在 Windows 11 上,仅用一张 RTX 5070 Ti 16GB 显卡,成功跑通了目前最强开源 MoE(混合专家)模型——Qwen3.6-35B-A3B。实测结果令人惊叹:
- 200,000 token 上下文
- 120 tokens/s 生成速度
- 显存占用仅 15.4 GB / 16 GB
这在三个月前,几乎没人敢想象这样的性能表现能够在一块消费级显卡上实现。本文将详细拆解这个方案的原理、部署方法和实测数据,帮助你在自己的电脑上复现这一成果,让你在家也能享受大语言模型的强大能力。
Qwen3.6-35B-A3B 模型详解
MoE 架构的优势
在深入讨论模型之前,有必要理解 MoE 架构的核心价值。传统的大语言模型采用的是稠密(Dense)架构,意味着每次推理都需要激活网络中的全部参数。这导致了一个矛盾:模型越大,能力越强,但推理成本也呈线性增长。
MoE 架构则打破了这个矛盾。它将模型拆分为多个独立的"专家"模块,每个专家专注于处理特定类型的问题。在推理时,一个轻量级的"路由器"(Router)会根据输入内容动态选择激活哪几个专家。这样,模型的总参数可以做得非常大,但实际参与计算的参数只有一小部分。
类比一下:传统稠密模型像是一个全才医生,什么病都要自己看;而 MoE 模型像是一个医院,里面有内科、外科、骨科等多个专科医生,根据病情分配给合适的科室。医院的规模可以很大(总参数多),但看一次病只需要看一个科室(激活参数少)。
什么是 MoE 架构?
MoE(Mixture of Experts,混合专家)是一种特殊的神经网络架构设计。传统的稠密模型在每次推理时会激活全部参数,而 MoE 模型则将参数分散到多个"专家"中,每次推理只选择性地激活一部分专家。
这种架构的核心优势在于:模型可以拥有巨大的总参数量,但实际推理时的计算量却很小。
Qwen3.6-35B-A3B 正是采用了这种稀疏 MoE 架构。它的总参数量达到 350 亿,但每次推理只激活约 30 亿参数。这意味着你在享受 35B 级别模型能力的同时,只需要付出 3B 级别的计算成本。
核心参数一览
| 指标 | 数值 |
|---|---|
| 总参数 | 350 亿(35B) |
| 激活参数 | 30 亿(3B) |
| 上下文窗口 | 200K(可扩展至 1M) |
| 开源协议 | Apache 2.0,商用无门槛 |
| 发布时间 | 2026 年 4 月 16 日 |
| 发布方 | 阿里通义千问团队 |
Apache 2.0 协议意味着你可以完全免费地将其用于商业用途,无需任何授权费用。这为个人开发者和中小企业提供了极大的便利。
性能表现:碾压同级对手
在四项智能体编程基准上,Qwen3.6-35B-A3B 的表现远超 Google 的 Gemma4-31B:
| 基准 | Qwen3.6 | Gemma4-31B | 差距 |
|---|---|---|---|
| Terminal-Bench 2.0 | 51.5 | 42.9 | +8.6 |
| SWE-bench Pro | 49.5 | 35.7 | +13.8 |
| SWE-bench Verified | 73.4 | 52.0 | +21.4 |
| SWE-bench Multilingual | 67.2 | 51.7 | +15.5 |
SWE-bench Verified 上领先超过 21 个百分点,这个差距是相当惊人的。在编程任务中,Qwen3.6 展现出了更强的代码理解和生成能力。
多模态能力同样出色。在视觉语言任务上,部分指标已经与 Claude Sonnet 4.5 持平。空间智能方面更为突出:RefCOCO 得分 92.0,ODInW13 得分 50.8。这些数据说明它不仅能处理文本,还能理解和推理图像内容。
这就是目前开源社区最强的「轻量高能」模型——用最小的算力,跑出最强的效果。
16GB 显存跑 35B 模型,到底怎么做到的?
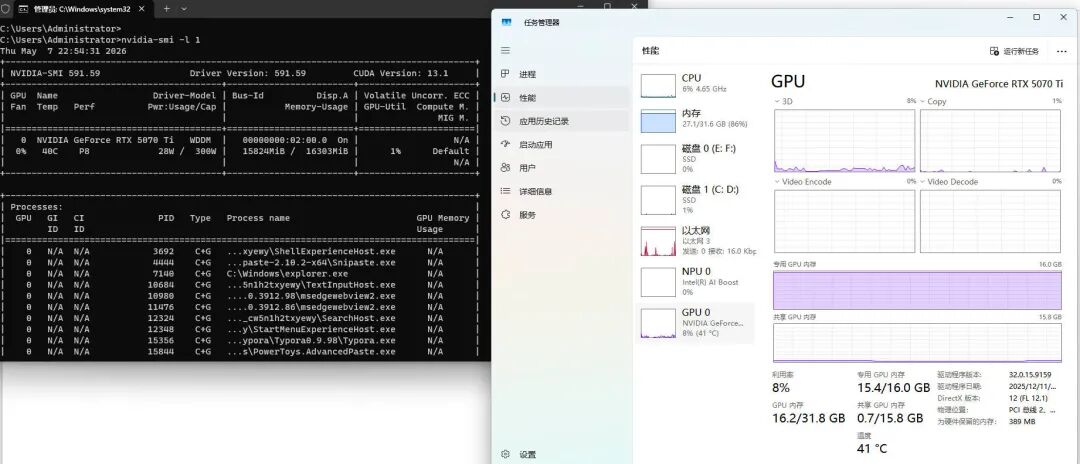
正常来说,一个 35B 参数的模型,如果使用 FP16(半精度浮点数)存储,需要 70GB 显存。就算使用 Q4 量化(4-bit 量化),也需要 17GB 以上显存。而 RTX 5070 Ti 只有 16GB。
但实测结果显示,不仅跑起来了,还支持 200K 的超长上下文。
实测数据如下:
| 指标 | 数值 |
|---|---|
| 模型 | Qwen3.6-35B-A3B(IQ3_S 量化,12.73GB) |
| 上下文窗口 | 200,000 tokens |
| GPU 显存占用 | 15.4 GB / 16 GB |
| Token 生成速度 | 120 tokens/s |
| 系统内存占用 | 约 15 GB |
这是一套低成本、高隐私、离线可用的完整方案。不需要购买几万块的专业 GPU,不需要租赁云端算力,在自己的电脑上就能运行世界级的大语言模型。
三大关键技术揭秘
能让 35B 模型在 16GB 显卡上流畅运行,靠的是三个精心选择的技术方案。每一个都不可或缺。
技术一:IQ3_S 量化方案
量化是将高精度的浮点数模型权重转换为低精度整数的过程,可以大幅减少模型的显存占用。
Qwen3.6-35B-A3B 使用了 llama.cpp 支持的 IQ3_S 量化格式,将 350 亿参数压缩到仅 12.73GB。这相当于每权重约 3.44 bits,在精度损失和体积压缩之间取得了完美的平衡。
为什么不是 Q4 或 Q5?因为 Q4 量化需要 17GB 以上,直接超过 16GB 显存上限。而 IQ2 虽然更小,但精度损失过大,输出质量无法接受。IQ3_S 刚好卡在 12.73GB,留下约 3.3GB 空间给 KV Cache,这就是那个"刚刚好"的甜蜜点。
少 1GB 都跑不起来,多 1GB 就要爆显存。 这个量化方案,是 16GB 显卡能用的前提条件。
技术二:KV Cache 压缩 —— TurboQuant
如果说模型权重是显存占用的大头,那么 KV Cache 就是长上下文场景下的隐形杀手。
KV Cache 是模型在推理过程中缓存的键值对数据,用于加速自注意力机制的计算。上下文越长,KV Cache 越大。对于 200K 的上下文,如果不做压缩,KV Cache 可以轻松吃掉十几 GB 显存。
解决方案是 llama.cpp 的 TurboQuant 技术:
--cache-type-k turbo3 --cache-type-v turbo3这个参数将 KV Cache 压缩到 3-bit。这意味着即使 200K tokens 的上下文,实际显存占用也被压到了一个可控的水平。
TurboQuant 还带来了一个隐藏福利:Cache 命中。只要是相同前缀的请求,系统会自动复用已经算好的 KV Cache。在连续对话和多轮交互场景中,Prompt 处理延迟可以降低到 87-317 毫秒,响应速度极快。
没有 TurboQuant,200K 上下文就是天方夜谭。
技术三:Blackwell 架构适配编译
RTX 5070 Ti 采用的是 NVIDIA 最新的 Blackwell 架构,Compute Capability 为 12.0a。编译 llama.cpp 时,必须正确指定架构参数,否则无法充分利用硬件性能,甚至直接编译失败。
关键编译参数:
# 指定 CUDA 架构
-DCMAKE_CUDA_ARCHITECTURES="120a"
# CUDA 12.8 兼容 VS 2026(需要绕过编译器检查)
-DCMAKE_CUDA_FLAGS="-allow-unsupported-compiler"
# Visual Studio 工具集版本
-T v145这三个参数缺一不可。少一个,编译就会报错。
速度实测数据
在不同场景下进行了详细的性能测试:
| 场景 | 速度/延迟 |
|---|---|
| Token 生成速度 | 120 tokens/s |
| Prompt 处理(Cache 命中) | 87-317 ms |
| Prompt 处理(冷启动) | 约 2 秒 |
120 tokens/s 的生成速度是什么概念?大约每秒能生成 60-80 个汉字。对于日常使用来说,这个速度几乎和人的阅读速度同步,体验非常流畅。
Cache 命中时的极低延迟(87-317 毫秒)意味着在多轮对话中,系统能几乎即时响应你的后续问题。这个体验远超大多数云端 API。
而且,这一切都不依赖任何特定客户端。只要你有一个能调 OpenAI API 兼容接口的工具,就能直接使用本地部署的 Qwen3.6。
应用场景分析
场景一:日常办公与创作
模型支持多模态输入输出,响应速度快,用来做以下事情非常合适:
- 文档撰写与编辑:写报告、写邮件、写方案,AI 助手随时在线
- 数据分析与处理:Excel 公式生成、数据清洗、趋势分析,效率提升数倍
- 代码生成与调试:Python、JavaScript、Go 等多种语言支持,Debug 建议精准到位
- 创意写作与内容创作:营销文案、社交媒体内容、故事创作,灵感源源不断
- 日常问答与信息检索:代替搜索引擎,直接给出精准答案
一张显卡搞定所有 AI 需求,无需再为各种 AI 工具付费。对于自由职业者和小型团队来说,这意味着每年可以节省数千元的 SaaS 订阅费用。
场景二:本地私密任务
对于隐私敏感的场景,本地部署是唯一可靠的选择:
- 企业内部文档问答:敏感业务数据不需要上传到云端
- 医疗记录分析:患者隐私数据严格本地处理
- 法律合同审查:合同内容不外泄
数据全程不离机,这才是本地部署最核心的价值。
场景三:低成本批量调用
对于需要大量 AI 能力的团队或工作室:
- 24 小时不间断服务
- 不需要按调用次数付费
- 不受云端 API 限流限制
- 边际成本趋近于零
一张卡,部署一次,永久使用。随着使用时间的增长,单次调用的成本会越来越低。
成本对比分析
硬件成本
一张 RTX 5070 Ti,京东售价约 7000 元人民币。
云端价格对比
| 方案 | 价格 |
|---|---|
| H100 80GB 租赁 | 约 $30/小时 |
| A100 80GB 租赁 | 约 $15/小时 |
| RTX 5070 Ti(一次性) | 约 ¥7000 |
粗略计算,租用 H100 跑 200 小时的费用就足够买一张 RTX 5070 Ti 了。而本地显卡可以 24/7 全天候运行,不限调用次数。
隐形成本
- 电费:RTX 5070 Ti 满载功耗约 300W,每小时电费不到 0.3 元
- 网络:不需要高速网络,离线即可使用
- 维护:一次部署,基本免维护
从长期使用的角度看,本地部署的经济效益非常明显。
部署踩坑指南
以下是实际操作中遇到的常见问题和解决方案,希望能帮你少走弯路。
坑一:GitHub 下载速度慢
模型文件和 llama.cpp 源码都托管在 GitHub 上,国内网络访问较慢。
解决方案: 使用 ghproxy.net 等代理加速下载。
坑二:编译环境配置
编译 llama.cpp 需要特定的环境配置。
解决方案: 必须使用 x64 Native Tools Command Prompt 进行编译。普通的 PowerShell 或 CMD 窗口会缺少必要的编译器环境变量,导致编译失败。
坑三:CMake 缓存问题
每次修改编译参数后,如果不清理旧的编译目录,CMake 会缓存之前的错误配置。
解决方案: 每次改参数前,删除 build 目录,重新从头编译。
坑四:CUDA 集成文件缺失
在某些系统配置下,Visual Studio 可能找不到 CUDA 的 BuildCustomizations 文件。
解决方案: 手动将 CUDA 的 BuildCustomizations 文件夹复制到 Visual Studio 的 MSBuild 目录下。
坑五:模型下载
Qwen3.6-35B-A3B 的 IQ3_S 量化版本体积较大(约 12.73GB),下载时间较长。
解决方案: 建议使用 HuggingFace 或 ModelScope 下载,配合代理或镜像站加速。
常见问题 FAQ
Q1:为什么必须用 IQ3_S 量化?
IQ3_S 在精度和体积之间取得了最佳平衡。Q4 量化需要 17GB 以上,超过 16GB 显存上限。IQ2 虽然更小,但精度损失过大,输出质量无法接受。IQ3_S 将模型压缩到 12.73GB,留下约 3.3GB 给 KV Cache,刚好够用。
Q2:TurboQuant 是什么?
TurboQuant 是 llama.cpp 中的 KV Cache 压缩技术,支持 turbo3 模式(3-bit 压缩)。对于长上下文场景,KV Cache 往往比模型权重本身更占显存,压缩 KV Cache 是跑大上下文的关键。
Q3:RTX 5070 Ti 之外的显卡能用吗?
理论上,任何 16GB 或以上显存的 NVIDIA 显卡都可以尝试。但需要注意架构适配,编译时需指定正确的 CUDA Architecture。RTX 4090(24GB)会更轻松,甚至可能跑更高精度的量化。AMD 显卡理论上也可以通过 ROCm 支持,但配置复杂度更高。
Q4:Windows 还是 Linux?
本文测试环境是 Windows 11。Linux 下编译和部署流程类似,但工具链配置可能略有不同。Linux 下通常不需要 -allow-unsupported-compiler 参数,且性能可能略优于 Windows。
Q5:显存不够用怎么办?
可以尝试以下方法:
- 使用更低的量化级别(如 IQ2_S),但会损失精度
- 减少上下文窗口大小(如从 200K 降到 100K)
- 使用系统内存作为补充( llama.cpp 支持 GPU+CPU 混合推理,但速度会明显下降)
Q6:能不能多卡并行?
可以。llama.cpp 支持多 GPU 并行推理。如果你有两张或多张显卡,可以使用 -ngl 参数分配层数到不同 GPU,进一步提升性能和可加载的模型规模。
总结
消费级显卡正在以肉眼可见的速度逼近专业算力。16GB 显存能跑 35B 模型 + 200K 上下文,那 24GB 呢?32GB 呢?明年今天,又能跑到什么程度?
模型在变小,量化在变强,架构在变聪明。曾经需要集群才能做的事,正在变成一张消费级显卡能做的事。这个进程,不会停止。
如果你想在自己的电脑上复现这个方案,核心步骤总结如下:
- 安装开发环境:Visual Studio 2026 Build Tools + CUDA 12.8 + CMake
- 编译 llama.cpp:使用正确的 Blackwell 架构参数
- 下载模型:获取 Qwen3.6-35B-A3B 的 IQ3_S 量化版本
- 启动推理:使用 turbo3 KV Cache 压缩参数启动
测试环境:Windows 11 + RTX 5070 Ti 16GB + VS2026 Build Tools + CUDA 12.8
实测日期:2026 年 5 月 7 日
大语言模型本地部署的时代已经到来。一张显卡,就是你的私人 AI 超级计算机。
原文链接: RTX 5070 Ti 跑通 Qwen3.6-35B-A3B
版权声明: 本文内容转载自微信公众号,版权归原作者所有,仅供学习交流。