V3来了!Claude-4.6-Opus蒸馏Qwen3.5,从"会思考"到"会干活" 🔥
📌 来源: 你好瓦力 公众号 | 转载说明: 本文经整理排版后发布,版权归原作者所有
- V1 炼丹: 学会了 Claude 的深度思考
- V2 升级: 让它想得更少答得更快
- V3 进化: 让它学会用工具干活 —— 从"会思考"到"会行动",质的飞跃
炼丹成本:一张 3060 就够,4090/A100 更舒服
📑 目录
- 写在前面
- V3 三大核心升级
- 一、硬件要求
- 二、环境安装
- 三、下载基座模型
- 四、准备数据集(V3 核心变化)
- 五、训练代码
- 六、阶段二:GRPO 工具调用强化训练
- 七、启动训练
- 八、模型导出
- 九、推理测试
- 十、ToolCall-15 工具调用测试
写在前面
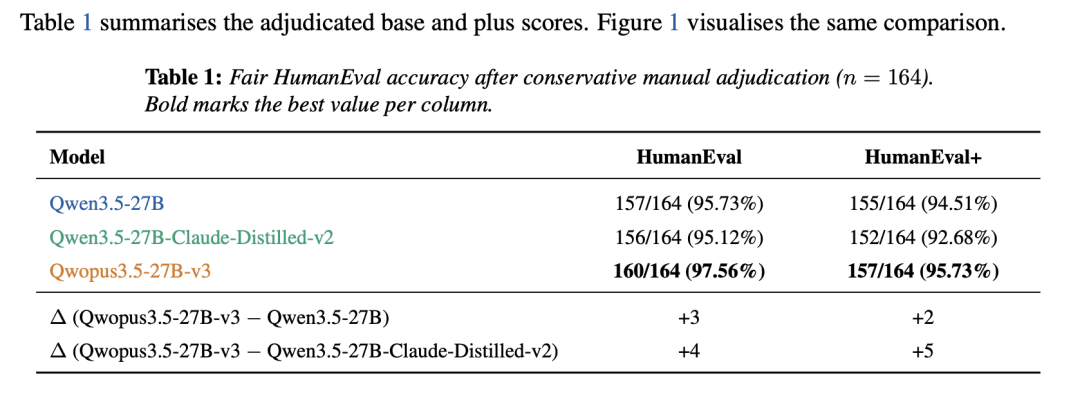
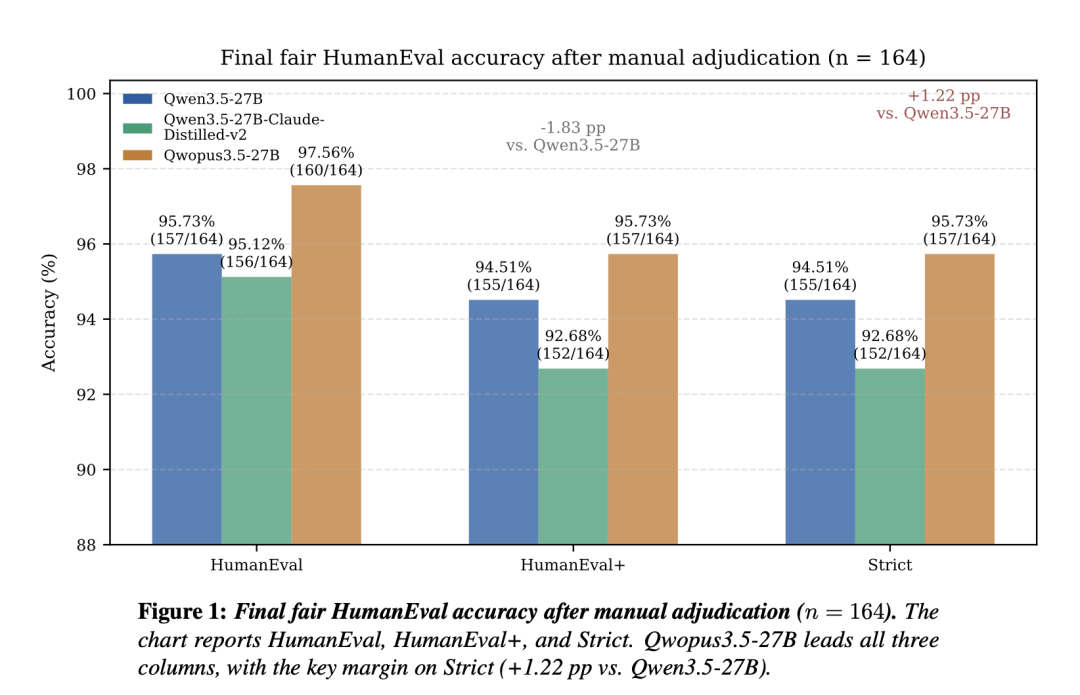
- V1(3 月底):证明了"小模型也能学到大模型的推理能力"——用 3,280 条 Claude 思维链数据,让 Qwen3.5-27B 学会了结构化推理。HumanEval 96.95%,单卡 3090 就能跑。
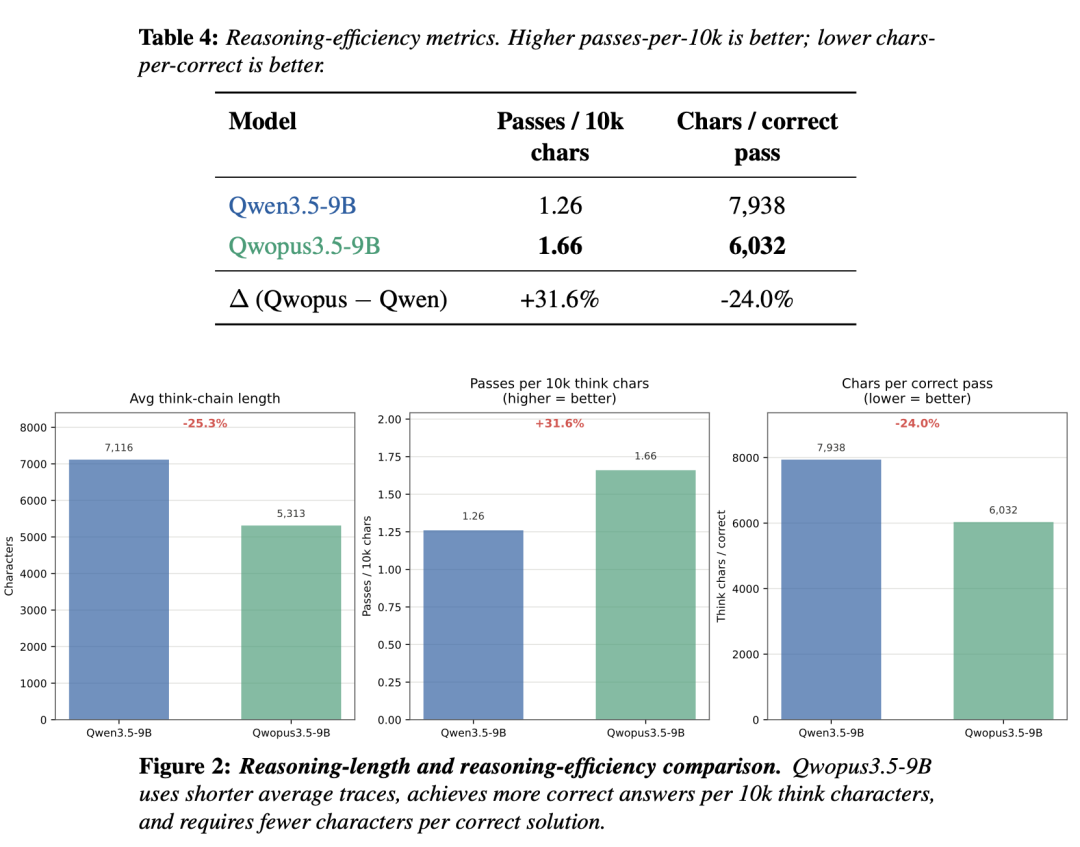
- V2(4 月初):证明了"推理效率可以大幅优化"——数据量翻 4 倍到 14,000 条,思维链缩短 24%,每 Token 正确率 +31.6%。代码准确率没掉,但每个 Token 更值钱了。
- V3(4 月 3 日):证明了"蒸馏模型也能做 Agent"——名字都换了,从拗口的
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled改成了 Qwopus3.5(Qwen + Opus 的合体)。同时发布 4B、9B、27B 三个尺寸,新增工具调用 RL 训练,从"想好再做"转向"做了再改"。
V3 的核心转变
从 "reason-then-act"(想好再做)到 "act-then-refine"(做了再改)
这个思路来自两篇重要研究:Reflexion 论文证明 Agent 通过"试错 + 反思"比纯内心推理更有效;另一项研究发现失败后反思再重试能带来 +34.7%(数学推理)和 +18.1%(函数调用)的提升。
下载量排行
| 模型 | 尺寸 | 下载量 | 点赞 |
|---|---|---|---|
| Qwopus3.5-9B-v3-GGUF | 9B | 43,478 | 178 |
| Qwopus3.5-27B-v3 | 27B | 5,073 | 106 |
| Qwopus3.5-9B-v3 | 9B | 3,463 | 61 |
| Qwopus3.5-4B-v3 | 4B | 897 | 5 |
9B GGUF 以 43k+ 下载量断崖式领先。16GB 内存的 MacBook 就能跑,Windows 上普通显卡也没压力。27B 虽然更强但门槛更高;4B 太小容易翻车。
9B 刚好在"能用"和"能跑"之间找到了最佳平衡。所以这篇教程,以 9B 为主线。
V3 三大核心升级
1. 结构化推理优化
V2 靠蒸馏 Claude 的思维链(CoT),但 Jackrong 在 V3 中坦诚指出了一个问题:V2 用的第三方蒸馏数据,有些思维链可能是"伪造"的——看起来像 Claude 生成的,实际上未必是。
学生模型去模仿这种"假推理",学到的可能只是表面的模式匹配。
V3 的做法:用精选的、可验证的推理链做训练,让模型学的是过程级推理,而非简单模仿答案。
| 对比 | V2 | V3 |
|---|---|---|
| 思维链来源 | 第三方蒸馏数据 | 精选可验证推理链 |
| 学习目标 | 模仿教师输出 | 学习过程级推理 |
| 推理风格 | 压缩式(可能伪造) | 显式、逐步、可验证 |
| 泛化能力 | 较弱 | 更强 |
2. 工具调用强化训练(V3 最重要的新增)
V3 专门做了针对工具调用的强化学习(RL)训练,为 Agent 框架(如 OpenClaw)优化了工具调用的稳定性和准确性。
这意味着 V3 在 Agent 场景下——比如自动搜索、调用 API、操作文件——比 V1/V2 强得多。ToolCall-15 测试 15/15 满分就是证据。
3. V1 → V2 → V3 全家族进化图谱
| 维度 | V1 | V2 | V3 |
|---|---|---|---|
| 名字 | Claude-4.6-Opus-Reasoning-Distilled | 同上 | Qwopus3.5 |
| 核心思路 | 蒸馏 Claude 推理能力 | 优化推理效率 | 工具调用 + 结构对齐 |
| 训练方法 | SFT + LoRA | SFT + LoRA | SFT + LoRA + RL(工具调用) |
| 基座模型 | Qwen3.5-27B | Qwen3.5-27B | Qwen3.5-9B(甜蜜点)/27B/4B |
| 数据量 | ~3,280 条 | ~14,000 条 | 高保真精选(24份策划数据集) |
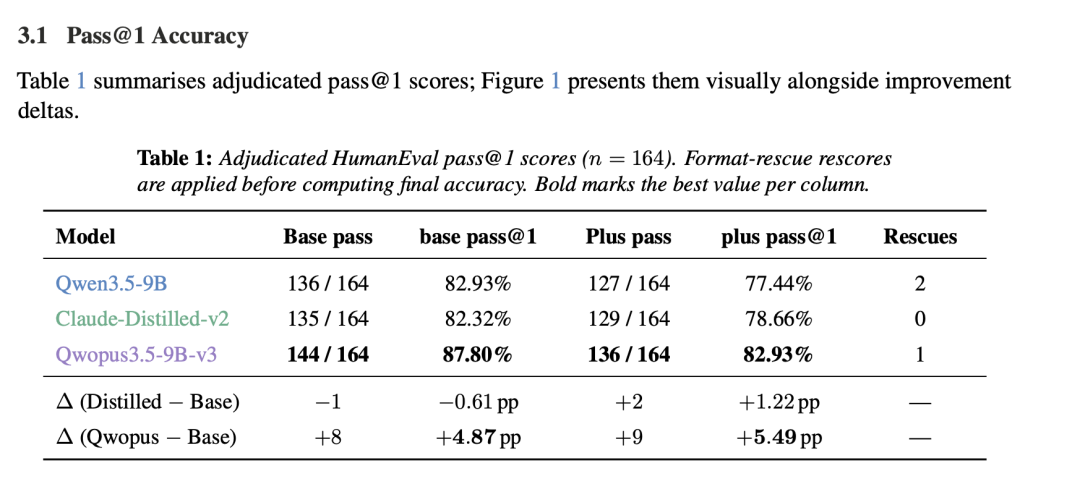
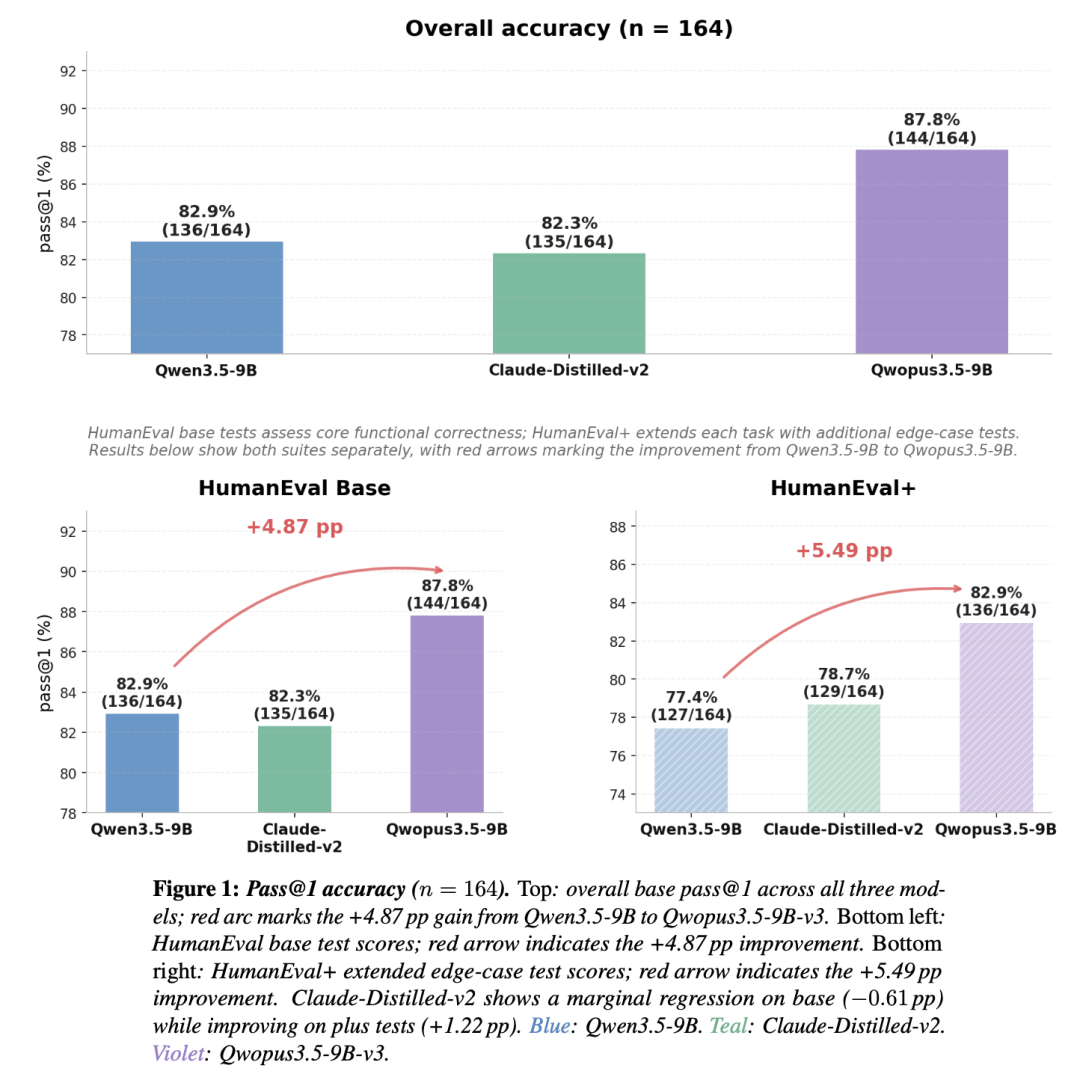
| HumanEval (9B) | ~82% | ~82% | 87.80% (+5pp) |
| HumanEval (27B) | 96.95% | 96.91% | 97.56% |
| MMLU-Pro | 基准 | -7.2% | +1.43% |
| 思维链长度 | 基准(长) | -24% | -25.3% |
| 工具调用 | 未优化 | 未优化 | 专项 RL 训练 (15/15) |
| 理念 | 模仿 Claude | 更快更省 | 做了再改 |
一、硬件要求
跑过 V1/V2 的同学注意:V3 主线是 9B,硬件门槛比之前的 27B 低得多!
9B 模型(本教程主线)
| 配置 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | 1× RTX 3060 (12GB) | 1× RTX 4090 (24GB) |
| 内存 | 16GB | 32GB+ |
| 磁盘 | 50GB SSD | 100GB+ NVMe SSD |
| CUDA | 12.1+ | 12.4+ |
27B 模型(可选,追求极致性能)
| 配置 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | 1× RTX 3090 (24GB) | 1× A100 (80GB) |
| 内存 | 32GB | 64GB+ |
| 磁盘 | 100GB SSD | 200GB+ NVMe SSD |
| CUDA | 12.1+ | 12.4+ |
训练方式对比
| 方式 | 9B 显存 | 27B 显存 | 适用人群 |
|---|---|---|---|
| QLoRA (4-bit) ★ | ~8GB | ~18GB | 大多数人(本教程主线) |
| LoRA (16-bit) | ~20GB | ~55GB | 有好卡的用户 |
| Full Fine-tuning | ~40GB+ | ~120GB+ | 多卡土豪 |
二、环境安装
跑过 V1/V2 的同学环境完全兼容,直接跳到第 3 步。
# Step 1:创建虚拟环境
conda create -n distill python=3.11 -y
conda activate distill
# Step 2:安装 PyTorch(根据你的 CUDA 版本选一个)
# CUDA 12.1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# CUDA 12.4(推荐)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
# Step 3:安装 Unsloth
pip install unsloth
# Step 4:安装其他依赖
pip install datasets accelerate bitsandbytes trl peft huggingface_hub
# Step 5:验证
python -c "
import torch
print(f'🔥 PyTorch: {torch.__version__}')
print(f'🎮 CUDA: {torch.cuda.is_available()}')
print(f'💪 GPU: {torch.cuda.get_device_name(0)}')
print(f'🧠 显存: {torch.cuda.get_device_properties(0).total_mem / 1024**3:.1f} GB')
print('✅ 环境就绪!')
"
# Step 6:登录 HuggingFace
huggingface-cli login💡 国内用户设镜像:
export HF_ENDPOINT=https://hf-mirror.com不知道 CUDA 版本?跑一下
nvidia-smi,右上角写着呢。
三、下载基座模型
V3 主线是 Qwen3.5-9B(不是 27B 了!)。Unsloth 提供了预量化版本,开箱即用。
QLoRA 方案(推荐,大多数人用这个)
from huggingface_hub import snapshot_download
snapshot_download('unsloth/Qwen3.5-9B-unsloth-bnb-4bit',
local_dir='./models/Qwen3.5-9B-4bit')
print('✅ 9B 4-bit 模型下载完成!约 5GB')LoRA 16-bit 方案(有大显存的用户)
from huggingface_hub import snapshot_download
snapshot_download('unsloth/Qwen3.5-9B',
local_dir='./models/Qwen3.5-9B')
print('✅ 9B 16-bit 模型下载完成!约 18GB')27B 用户把模型名改成
unsloth/Qwen3.5-27B-unsloth-bnb-4bit(~15GB)或unsloth/Qwen3.5-27B(~55GB)。
四、准备数据集(V3 核心变化)
V3 的数据策略:从"量多"到"质精"
V3 和 V1/V2 最大的区别在于数据质量。V1/V2 用的第三方蒸馏数据可能包含"伪造"推理链,V3 改用 Jackrong 精心策划的高保真数据集。
Jackrong 在 GitHub 上开源了 24 份高保真蒸馏数据集,涵盖:
| 类别 | 代表数据集 | 用途 |
|---|---|---|
| 推理 & CoT | Jackrong/Qwen3.5-reasoning-700x | 逐步推理能力 |
| 数学 & STEM | DeepSeek-v3.1-reasoner-Distilled-math-samples | 数学/科学推理 |
| 代码 & 算法 | Competitive-Programming-python-blend | 编程能力 |
| 多轮对话 | LogicMind-Chat-Reasoning-SFT-300K | 对话能力 |
方案 A:轻量版(推荐新手,~14,000 条)
from datasets import load_dataset, concatenate_datasets
print('📥 正在下载 V3 训练数据...')
ds1 = load_dataset('nohurry/Opus-4.6-Reasoning-3000x-filtered', split='train')
print(f' 📚 数据集 1: {len(ds1)} 条 ✅ ← Claude Opus 深度推理轨迹')
ds2 = load_dataset('Roman1111111/claude-opus-4.6-10000x', split='train')
print(f' 🆕 数据集 2: {len(ds2)} 条 ✅ ← 大规模通用推理')
ds3 = load_dataset('TeichAI/claude-4.5-opus-high-reasoning-250x', split='train')
print(f' 🧠 数据集 3: {len(ds3)} 条 ✅ ← 高难度结构化推理')
ds4 = load_dataset('Jackrong/Qwen3.5-reasoning-700x', split='train')
print(f' 🔧 数据集 4: {len(ds4)} 条 ✅ ← 多样性推理补充')
combined = concatenate_datasets([ds1, ds2, ds3, ds4])
combined.save_to_disk('./data/combined_opus_reasoning_v3')
print(f'🎉 合并完成!共 {len(combined)} 条训练数据')方案 B:高保真版(进阶用户,更接近 V3 原版)
# 克隆 Jackrong 的训练仓库
git clone https://github.com/R6410418/Jackrong-llm-finetuning-guide.git
cd Jackrong-llm-finetuning-guide
# 一键下载全部 24 份高保真数据集
pip install huggingface_hub
python download_datasets.py💡 下载大小:方案 A 约 200-300MB,方案 B 约 1-2GB。国内用户记得设
HF_ENDPOINT镜像。
数据格式
每条数据都是标准 messages 格式:
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Solve: if 3x + 7 = 22, find x..."},
{"role": "assistant", "content": "<think>\nLet me analyze this request carefully:\n1. I need to solve for x in 3x + 7 = 22\n2. Subtract 7: 3x = 15\n3. Divide by 3: x = 5\n4. Verify: 3(5) + 7 = 22 ✓\n</think>\n\nx = 5"}
]
}关键是 <think>...</think> 标签——Claude 的结构化推理过程。V3 强调这些推理链必须是可验证的、过程级的。
五、训练代码
V3 的训练分为两个阶段:
- 阶段一:SFT + LoRA(和 V1/V2 一脉相承,基本盘)
- 阶段二:GRPO 工具调用强化学习(V3 新增,让模型学会用工具)
完整训练代码 train_v3.py
# ============================================================
# 🔥 train_v3.py - Qwopus3.5 蒸馏训练 (V3)
#
# V3 变化:
# - 基座模型:9B(甜蜜点),不再是 27B
# - 数据:高保真推理链(可验证、过程级)
# - 新增:工具调用 RL 训练(阶段二另外跑)
#
# 使用方法:改完配置区,直接 python train_v3.py
# 预计时间:9B + 3060 约 2-3 小时,4090 约 1-2 小时
# ============================================================
from unsloth import FastLanguageModel
from datasets import load_dataset, concatenate_datasets
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
# ╔══════════════════════════════════════════════════════════╗
# ║ 🎛️ 配置区 ║
# ║ 只需要改这里!其他代码不用动! ║
# ╚══════════════════════════════════════════════════════════╝
# --- 🖥️ 模型配置 ---
MODEL_NAME = "unsloth/Qwen3.5-9B-unsloth-bnb-4bit" # ← V3 主线:9B
# MODEL_NAME = "unsloth/Qwen3.5-9B" # 16-bit LoRA 用这个
# MODEL_NAME = "unsloth/Qwen3.5-27B-unsloth-bnb-4bit" # 27B 土豪用这个
MAX_SEQ_LENGTH = 4096 # 序列长度(显存不够就改 2048)
LOAD_IN_4BIT = True # True = QLoRA(省显存), False = LoRA(需大显存)
# --- 🧬 LoRA 配置 ---
LORA_R = 64 # LoRA Rank
LORA_ALPHA = 64 # 一般跟 r 保持一致
LORA_DROPOUT = 0 # Unsloth 优化过了,放心填 0
# --- 📊 训练超参数 ---
NUM_EPOCHS = 3 # 训练 3 轮
BATCH_SIZE = 2 # 每批 2 条(9B 显存友好,3060 用 1)
GRAD_ACCUM = 4 # 梯度累积 4 步(等效 batch = 8)
LEARNING_RATE = 2e-4 # 学习率
WARMUP_STEPS = 10 # 预热步数
OUTPUT_DIR = "./output_v3"
LOGGING_STEPS = 5
# ==================== 📦 加载基座模型 ====================
print("🚀 正在加载 Qwen3.5-9B,请稍候...")
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=MODEL_NAME,
max_seq_length=MAX_SEQ_LENGTH,
dtype=None,
load_in_4bit=LOAD_IN_4BIT,
)
print(f"✅ 模型加载完成: {MODEL_NAME}")
# ==================== 🧬 配置 LoRA ====================
model = FastLanguageModel.get_peft_model(
model,
r=LORA_R,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)
model.print_trainable_parameters()
# ==================== 📚 加载数据集(V3 版本) ====================
print("📥 加载 V3 训练数据集...")
ds1 = load_dataset("nohurry/Opus-4.6-Reasoning-3000x-filtered", split="train")
ds2 = load_dataset("Roman1111111/claude-opus-4.6-10000x", split="train")
ds3 = load_dataset("TeichAI/claude-4.5-opus-high-reasoning-250x", split="train")
ds4 = load_dataset("Jackrong/Qwen3.5-reasoning-700x", split="train")
dataset = concatenate_datasets([ds1, ds2, ds3, ds4])
print(f"📊 共加载 {len(dataset)} 条训练数据")
# ==================== 🔄 格式化数据 ====================
def formatting_prompts_func(examples):
convos = examples["messages"]
texts = []
for convo in convos:
text = tokenizer.apply_chat_template(
convo, tokenize=False, add_generation_prompt=False,
)
texts.append(text)
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
# ==================== 🎯 配置训练器 ====================
from unsloth import train_on_responses_only
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=TrainingArguments(
output_dir=OUTPUT_DIR,
num_train_epochs=NUM_EPOCHS,
per_device_train_batch_size=BATCH_SIZE,
gradient_accumulation_steps=GRAD_ACCUM,
learning_rate=LEARNING_RATE,
warmup_steps=WARMUP_STEPS,
lr_scheduler_type="cosine",
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
optim="adamw_8bit",
logging_steps=LOGGING_STEPS,
save_strategy="steps",
save_steps=200,
save_total_limit=3,
weight_decay=0.01,
max_grad_norm=1.0,
seed=3407,
report_to="none",
),
dataset_text_field="text",
max_seq_length=MAX_SEQ_LENGTH,
packing=False,
)
# 🔥 核心技巧:只在 assistant 回答上计算 loss
trainer = train_on_responses_only(
trainer,
instruction_part="<|im_start|>user\n",
response_part="<|im_start|>assistant\n",
)
# ==================== 🔥 开始训练 ====================
print("🔥 V3 SFT 训练开始!")
trainer_stats = trainer.train()
print(f"🎉 训练完成!最终 Loss: {trainer_stats.training_loss:.4f}")
# ==================== 💾 保存 ====================
model.save_pretrained("./output_v3/lora_adapter")
tokenizer.save_pretrained("./output_v3/lora_adapter")
print("✅ V3 LoRA 适配器已保存到 ./output_v3/lora_adapter")六、阶段二:GRPO 工具调用强化训练(V3 新增)
这是 V3 区别于 V1/V2 的关键一步。
为什么需要 RL?
SFT 教会了模型"怎么思考",但 Agent 场景还需要模型"怎么用工具":
- 在给定工具列表时,选对工具
- 参数传对(比如用户要华氏温度,你传了
fahrenheit没?) - 能串联多个工具完成复杂任务
- 不该用工具时能忍住
- 工具报错了知道换策略
GRPO 训练代码
# ============================================================
# 🔥 train_v3_grpo.py - Qwopus3.5 工具调用强化训练
# ============================================================
from unsloth import FastLanguageModel
from trl import GRPOConfig, GRPOTrainer
# 加载阶段一训练好的模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="./output_v3/lora_adapter",
max_seq_length=4096,
dtype=None,
load_in_4bit=True,
)
# GRPO 配置
grpo_config = GRPOConfig(
output_dir="./output_v3_grpo",
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=5e-5, # RL 阶段学习率要小一些
logging_steps=10,
save_steps=100,
max_completion_length=2048,
num_generations=4, # 每个 prompt 生成 4 个候选
report_to="none",
)
# 工具调用奖励函数
def tool_call_reward(completions, **kwargs):
rewards = []
for completion in completions:
score = 0.0
text = completion[0]["content"] if isinstance(completion, list) else completion
if "<tool_call>" in text and "</tool_call>" in text:
score += 0.5
if "<think>" in text:
score += 0.3
if len(set(text.split())) / max(len(text.split()), 1) > 0.3:
score += 0.2
rewards.append(score)
return rewards
trainer = GRPOTrainer(
model=model,
config=grpo_config,
reward_funcs=[tool_call_reward],
train_dataset=tool_prompts, # 需要构造工具调用场景数据
tokenizer=tokenizer,
)
trainer.train()
model.save_pretrained("./output_v3_grpo/lora_adapter")
print("✅ GRPO 工具调用强化训练完成!")⚠️ 重要说明:
- GRPO 训练是可选步骤。如果你只需要推理能力(不需要 Agent/工具调用),阶段一的 SFT 就够了。
- GRPO 对显存要求更高,9B 建议至少 16GB 显存。
- Jackrong 的 GitHub 仓库(
R6410418/Jackrong-llm-finetuning-guide)有完整训练 notebook。
七、启动训练
直接运行
conda activate distill
python train_v3.py后台运行(推荐,防止 SSH 断开翻车)
# tmux 方式(强烈推荐)
tmux new -s distill-v3
python train_v3.py
# Ctrl+B, D 脱离会话(训练继续跑)
# tmux attach -t distill-v3 回来看
# nohup 方式
nohup python train_v3.py > train_v3.log 2>&1 &
tail -f train_v3.log⚠️ 一定要用 tmux 或 nohup,SSH 断了就白跑了。
训练时间参考(9B 模型,~14,000 条数据)
| GPU | QLoRA 时间 | LoRA 时间 |
|---|---|---|
| RTX 3060 12GB | 3-5 小时 | N/A(显存不够) |
| RTX 3090 24GB | 2-3 小时 | 3-4 小时 |
| RTX 4090 24GB | 1-2 小时 | 2-3 小时 |
| A100 80GB | 0.5-1 小时 | 1-2 小时 |
Loss 走势参考
Step 5 | Loss: 2.34 ← 刚开始,偏高正常
Step 50 | Loss: 0.85 ← 开始收敛
Step 200 | Loss: 0.55 ← 趋于稳定
Step 500 | Loss: 0.45 ← 持续优化
最终 | Loss: 0.3~0.7 ← 理想范围- 持续下降 → 正常
- 降到 0 → 过拟合了,减少 epochs 或加数据
- 纹丝不动 → 检查数据格式和学习率
八、模型导出
方式一:导出 GGUF(推荐,用 Ollama/LM Studio 跑)
# 🔑 V3 关键:工具调用场景推荐 Q6_K
model.save_pretrained_gguf(
"./output_v3/gguf",
tokenizer,
quantization_method="q6_k",
)
print("✅ GGUF 模型已导出!")9B 量化方式怎么选?
| 量化 | 文件大小 | 推理显存 | 精度 | 推荐场景 |
|---|---|---|---|---|
| Q4_K_M | ~5.6GB | ~6GB | 中 | 极致省显存 |
| Q5_K_S | ~6.3GB | ~7GB | 较高 | 日常使用 |
| Q6_K | ~7.4GB | ~8GB | 高 | 工具调用首选 |
| Q8_0 | ~9.5GB | ~10GB | 高 | 追求极致精度 |
| BF16 | ~17.9GB | ~18GB | 完整精度 | 显存豪华配置 |
⚠️ V3 量化建议: Q6_K 是工具调用场景的最优量化精度。低于 Q6 的量化在复杂工具调用时可能出现参数精度下降。
方式二:合并为完整模型
model.save_pretrained_merged(
"./output_v3/merged_model",
tokenizer,
save_method="merged_16bit", # 9B 约 18GB
)九、推理测试
方式一:Unsloth 直接推理
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="./output_v3/lora_adapter",
max_seq_length=4096, dtype=None, load_in_4bit=True,
)
FastLanguageModel.for_inference(model)
messages = [
{"role": "system", "content": "You are a helpful assistant that thinks step by step."},
{"role": "user", "content": "请用 Python 实现一个 LRU Cache,要求 O(1) 的 get 和 put 操作"},
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs, max_new_tokens=4096,
temperature=0.6, top_p=0.95, top_k=20,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)验证要点:
- 回复里有
<think>...</think>结构化思维链 → 蒸馏成功 - 思维链是结构化的(列大纲、分步骤) → V3 特性生效
- 代码答案正确 → 推理能力迁移成功
方式二:Ollama 部署(日常使用推荐)
# 创建 Modelfile
cat > Modelfile_v3 << 'EOF'
FROM ./output_v3/gguf/unsloth.Q6_K.gguf
PARAMETER temperature 0.6
PARAMETER top_p 0.95
PARAMETER top_k 20
PARAMETER num_ctx 32768
SYSTEM "You are a helpful assistant that thinks step by step."
EOF
# 创建并运行
ollama create my-qwopus-v3 -f Modelfile_v3
ollama run my-qwopus-v3也可以直接用官方 GGUF:
ollama run hf.co/Jackrong/Qwopus3.5-9B-v3-GGUF:Q6_K十、ToolCall-15 工具调用测试(V3 专属)
什么是 ToolCall-15?
- 15 个场景,覆盖 5 大类能力
- 12 个工具,模型每次都能看到全部工具
- Temperature 设为 0,排除随机性
五大考核维度
| 维度 | 考什么? | 举例 |
|---|---|---|
| 工具选择 | 能不能选对工具? | 问天气,该用 get_weather 还是 web_search? |
| 参数精度 | 参数传对了吗? | 用户要华氏温度,你传了 fahrenheit 没? |
| 多步链式 | 能不能串联多个工具? | 搜文件 → 读内容 → 查联系人 → 发邮件 |
| 克制与拒绝 | 不该用工具时能忍住吗? | "二战哪年结束?"你别去搜啊 |
| 错误恢复 | 工具报错了怎么办? | 搜索没结果,是放弃还是换关键词? |
实测结果
Qwopus3.5-9B-v3(Q8 量化)在 ToolCall-15 上拿了 15/15 满分——和 27B 版本持平!
自己跑一遍
git clone https://github.com/stevibe/ToolCall-15.git
cd ToolCall-15
npm install
cp .env.example .env
# 配置 .env 中的模型地址
npm run dev
# 打开 http://localhost:3000独立 Benchmark:SQL 生成能力测试
| 模型 | 量化 | 得分(/25) |
|---|---|---|
| Qwopus3.5-27B-v3 | Q3_K_M | 23 |
| Qwopus3.5-27B-v2 | Q4_K_M | 22 |
| Qwopus3.5-9B-v3 | Q8_0 | 17 |
| Qwen3.5-9B(基线) | — | 5 |
9B 蒸馏版拿到 17 分,是基线 Qwen3.5-9B(5 分)的 3.4 倍。
已知兼容性问题
- vLLM 部署: 多位用户反映 tokenizer_class 错误。临时方案:手动将
tokenizer_config.json中的tokenizer_class改为Qwen2Tokenizer。即使修复后,vLLM 的工具调用功能仍不可用。建议使用 Ollama 或 LM Studio 部署。 - Thinking 开关: 使用 GGUF 版本时,
enable_thinking: false参数不生效,模型仍然输出思维链。这是 GGUF 格式的已知限制。 - 9B Agent 稳定性: 9B Q8_0 作为 Agent 使用时,会出现代码生成错误和上下文混乱。复杂多轮 Agent 场景下稳定性仍不如 27B。
总结
从 V1 的推理蒸馏,到 V2 的效率优化,再到 V3 的工具调用——三个版本走下来,数据足以支撑结论:
- ✅ HumanEval 87.80%(9B),比原版 Qwen3.5-9B 高了近 5 个百分点
- ✅ MMLU-Pro 81.79%,通用知识反超基线(V2 掉的 7.2% 补回来了)
- ✅ 推理效率 +31.7%,每个正确答案的 Token 成本降低 24%
- ✅ ToolCall-15 满分 15/15,9B 打出了 27B 的水平
- ✅ 9B + Q6_K 只需 ~8GB 显存推理,16GB 内存 MacBook 就能跑
Jackrong 在模型卡里写的一段话:
"没有人一开始就是专家。但每一个专家,都曾勇敢地迈出了第一步。"
📢 原文作者: 你好瓦力 | 基于 Jackrong 的开源工作整理,感谢 Unsloth 团队、老章、以及所有数据集贡献者
📌 更多教程请访问: AiTimes 智能时代