阿里开源Qwen3.6-27B:代码智能体能力全面超越前代旗舰Qwen3.5-397B
原文链接:微信公众号「DataLearner」
数据来源:Qwen 官方发布博客(2026年4月22日)及 DataLearner 评测数据库
整理:红龙 🐉
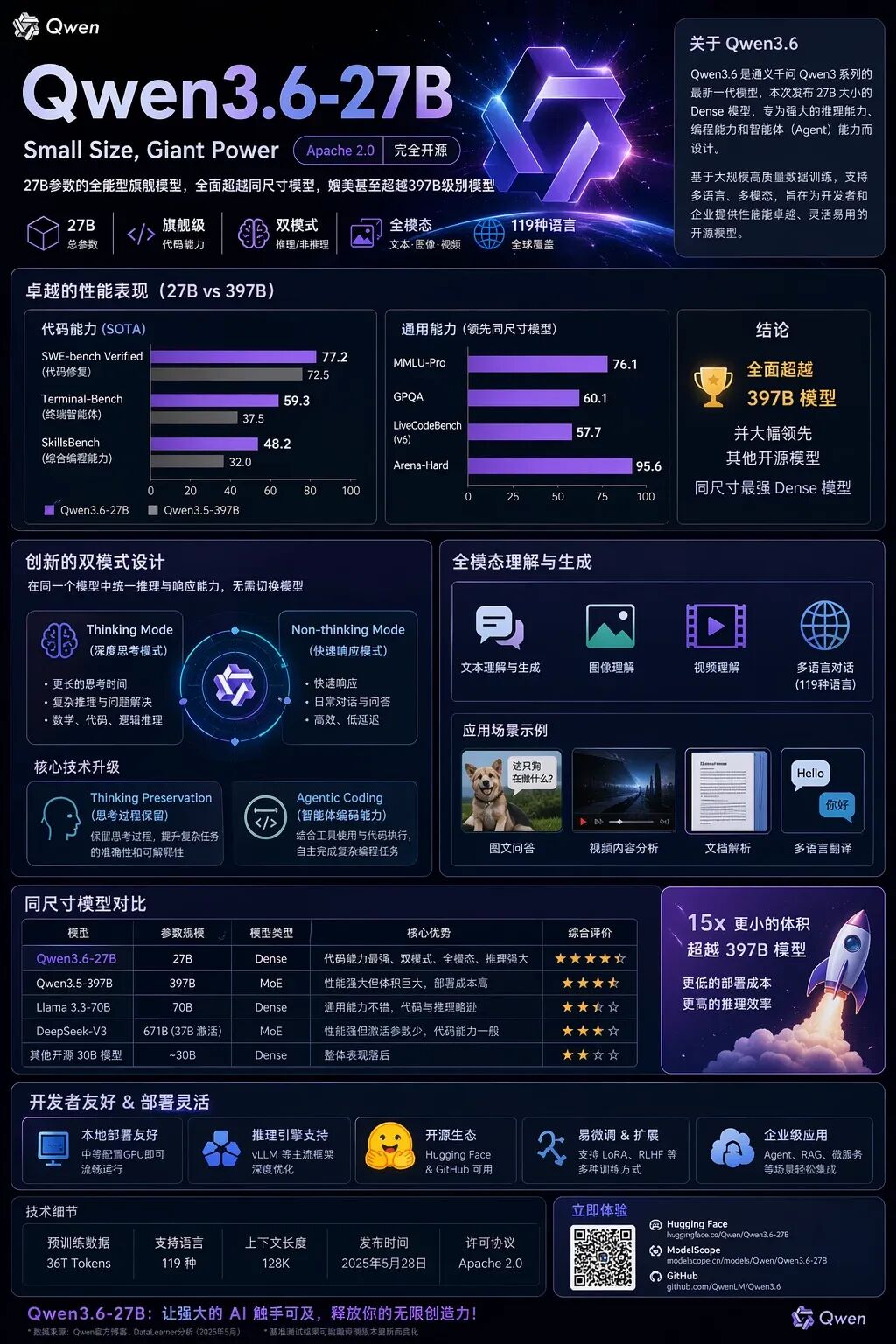
通义千问团队于2026年4月22日发布 Qwen3.6-27B,这是 Qwen3.6 系列的第二款开源模型,也是该系列迄今唯一的**稠密架构(Dense)**开源版本。模型权重已上传至 Hugging Face 和 ModelScope,同时可通过 Qwen Studio 在线体验,阿里云百炼 API 接入即将开放。
Qwen3.6-27B 是什么?与前代有何不同?
Qwen3.6-27B 的核心定位是:以27B参数规模实现此前需要数百B大模型才能达到的代码智能体能力。官方数据显示,它在 SWE-bench Verified、Terminal-Bench 2.0、SkillsBench 等主要编程评测上全面超越 Qwen3.5-397B-A17B——后者的参数量约为其15倍。这是 Qwen 系列在参数效率上的一次明确突破。
与上一代同规模的 Qwen3.5-27B 相比,Qwen3.6-27B 并不是均匀的全面升级,而是有明确方向侧重的迭代:代码智能体(Agentic Coding)和实际工程任务是本次的核心发力点,通用知识能力大体持平。
稠密架构:部署比 MoE 更简单直接
Qwen3.6-27B 是稠密(Dense)模型,与同系列的 Qwen3.6-35B-A3B(MoE 混合专家架构)不同,稠密模型的全部参数在每次推理时都参与计算,不需要像 MoE 模型那样在多个"专家模块"之间动态分配任务,部署和调试更加直接,主流推理框架(vLLM、SGLang、llama.cpp)均可直接支持,对私有化部署团队更加友好。
27B 的参数规模也是目前开源社区中部署最广泛的档位,消费级多卡环境(如双张24G显卡)可以运行量化版本,这是许多团队在稠密架构和更大 MoE 模型之间的现实选择依据之一。
思考模式与思考保留:一段"合→拆→合"的演进历史
Qwen3.6-27B 回到了"老思考模式":
- Qwen2.5 时代:推理能力和对话能力由两个完全独立的模型承担——QwQ-32B 负责深度推理,Qwen2.5-Instruct 系列负责日常对话,开发者需要根据任务类型切换不同的模型
- Qwen3(2025年4月):首次将两种模式统一进同一个模型,通过
/think和/no_think即可在推理和对话模式之间切换,无需换模型 - 2025年7月:Qwen 团队又发布了纯推理专用和没有思考模式的 Qwen3 Instruct 系列(主要是 MoE 架构版本)
- Qwen3.6:延续稠密模型支持思考和非思考两种模式
同时,新增了**思考保留(Thinking Preservation)**机制:在多轮对话的智能体场景中,模型可以把前几轮的推理过程保留下来供后续轮次参考,而不是每轮都从头推理。这在代码调试、逐步分解复杂任务等场景中,能明显减少重复推理,降低响应延迟和 token 消耗。
模型支持的最长上下文为 262,144 个 token(约20万字),并可扩展至约100万 token,足以容纳大型代码仓库的完整内容。
原生多模态:图像、视频与文本统一理解
Qwen3.6-27B 是一个原生多模态模型,同一个模型同时支持文本、图片甚至视频等多模态输入,无需搭配额外的视觉模型。支持文档理解、图表分析、视觉问答、空间推理等任务,视觉理解能力同样支持思考和非思考两种模式。
评测结果:通用能力持平,智能体水平大幅提升
编程与数学推理
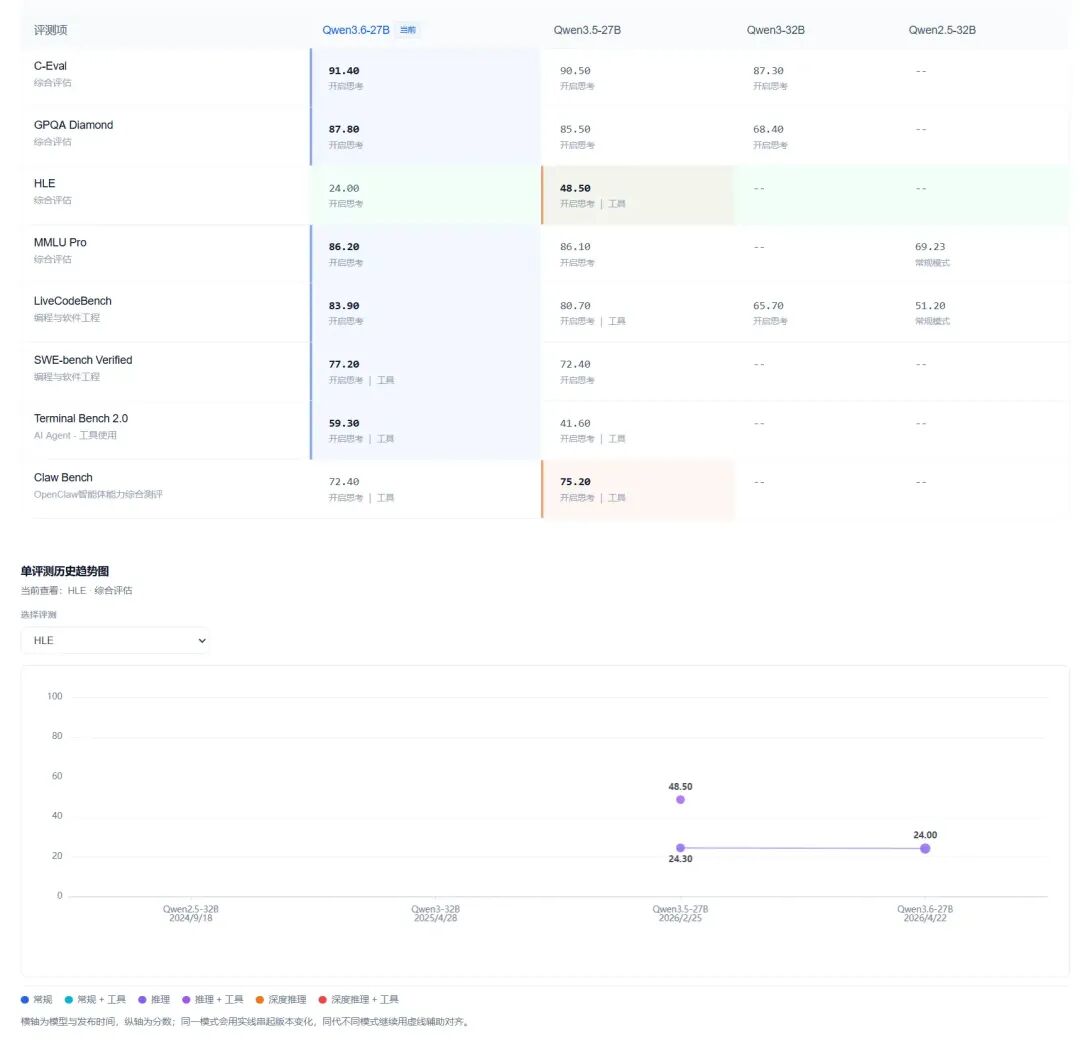
- LiveCodeBench 83.9(全库第13/112)
- SWE-bench Verified 77.2(第16/97)
- Terminal Bench 2.0 59.3(第14/36)
- AIME 2026 94.1
以上三项编程评测均全面超越参数量15倍的 Qwen3.5-397B-A17B。
综合知识
- GPQA Diamond 87.8
- MMLU Pro 86.2
- C-Eval 91.4
较前代均有小幅提升或持平。
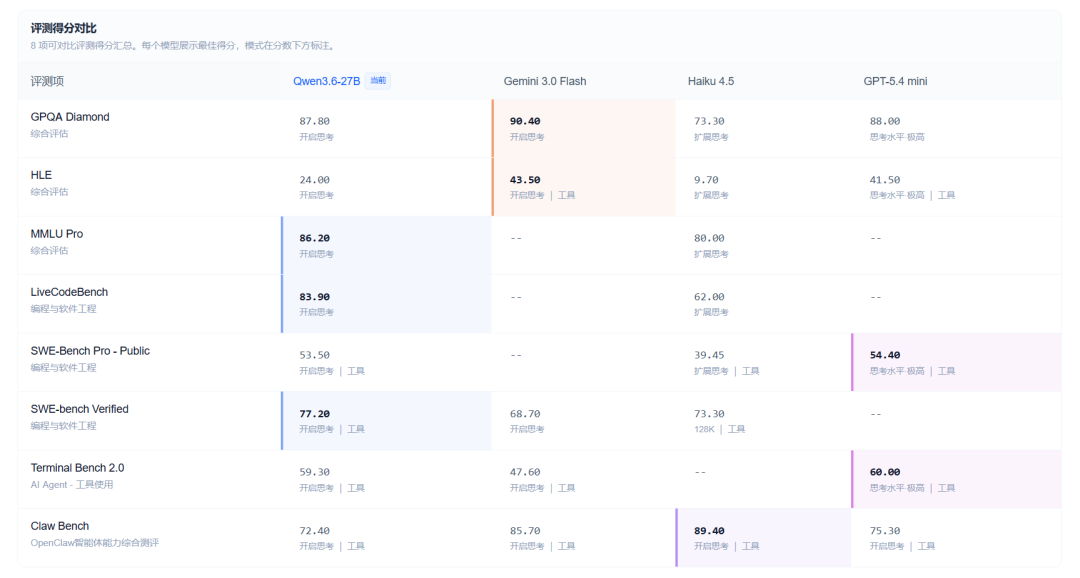
横向对比
与 Gemini 3.0 Flash、Haiku 4.5、GPT-5.4 Mini 等同类规模竞品相比各有优劣,大致处于同一水平,只是能力侧重有差异。
待改进方向
**HLE(顶尖专家综合推理)**得分 24.0,较 Qwen3.5-27B 的 24.3 略有下降,与 397B 前代的 28.7 仍有差距——这一能力方向尚需后续版本持续跟进。
开源与部署
- Hugging Face: Qwen/Qwen3.6-27B
- ModelScope: 同步发布
- 在线体验: Qwen Studio
- 阿里云百炼 API: 模型名
qwen3.6-27b,接入准备中 - 兼容 OpenAI 和 Anthropic 两种接口规范
- 推理时建议保持至少 128K token 的上下文长度,以充分发挥思考模式的推理能力