性能实测:多台 Mac 本地运行 80B 大模型
作者:Manjunath Janardhan | 译者:Carl Cui 来源:楠楠自瑜 发布日期:2026-03-30
📖 目录
exo 是什么
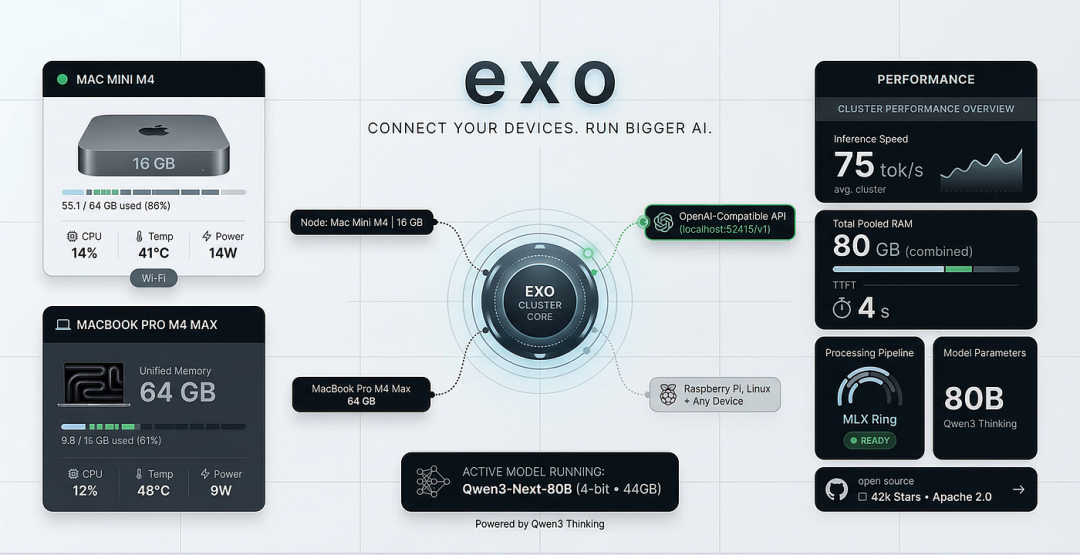
exo 是一个由 Exo Labs 维护的开源项目,一句话概括:它将你所有的设备连接成个人 AI 集群,让你能够运行任何单台机器都无法容纳的模型。
核心功能
| 功能 | 说明 |
|---|---|
| 自动设备发现 | 运行 exo 的设备可在网络上自动相互发现,无需手动配置 |
| Thunderbolt RDMA | 在 M4 Pro/Max 硬件上,实现 99% 延迟降低 |
| 拓扑感知自动并行 | 根据可用 RAM、CPU、GPU 及网络延迟,确定最佳模型分片方式 |
| Tensor 并行 | 2 台设备加速 1.8 倍,4 台设备加速 3.2 倍 |
| MLX 支持 | 使用 MLX 作为推理后端,MLX 分布式进行分布式通信 |
| 多 API 兼容 | OpenAI Chat、Claude Messages、OpenAI Responses、Ollama API |
| 自定义模型 | 从 HuggingFace hub 加载自定义模型 |
| 支持 54+ 模型 | 从小型 Llama 到 671B DeepSeek 变体 |
硬件配置
通过 exo,作者配对了两台机器:
| 设备 | 内存 | 使用率 |
|---|---|---|
| Mac Mini M4 | 16GB 统一内存 | 9.8GB/16GB (61%) |
| MacBook Pro M4 Max | 64GB 统一内存 | 55.1GB/64GB (86%) |
运行模型: Qwen3-Next-80B-A3B-Thinking-4bit(44GB 量化模型)
性能表现
| 指标 | 数据 |
|---|---|
| 推理速度 | 70–80 tokens/秒 (TPS) |
| TTFT | 4–11 秒(根据查询复杂度) |
| Mac Mini 温度 | 41–86°C(峰值负载) |
| MacBook Pro 温度 | 48–53°C(稳定) |
入门指南
Mac 设备设置
exo 为 macOS 提供原生应用程序:
要求: macOS Tahoe 26.2 或更高版本
安装步骤:
- 从发布页面下载
EXO-latest.dmg - 复制到应用程序文件夹并启动
- 在其他机器上重复操作
- 节点自动发现并显示在拓扑视图
Linux 和 Windows 设置
目前 Linux 仅支持 CPU 运行,GPU 支持正在开发中。
前置依赖:
| 依赖 | 安装命令 |
|---|---|
| uv (Python 依赖管理) | `curl -LsSf https://astral.sh/uv/install.sh |
| node (构建控制面板) | sudo apt update && sudo apt install nodejs npm |
| rust (Rust 绑定) | `curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs |
构建并运行:
# Clone exo
git clone https://github.com/exo-explore/exo
# Build dashboard
cd exo/dashboard && npm install && npm run build && cd ..
# Run exo
uv run exo控制面板地址:http://localhost:52415/
控制面板
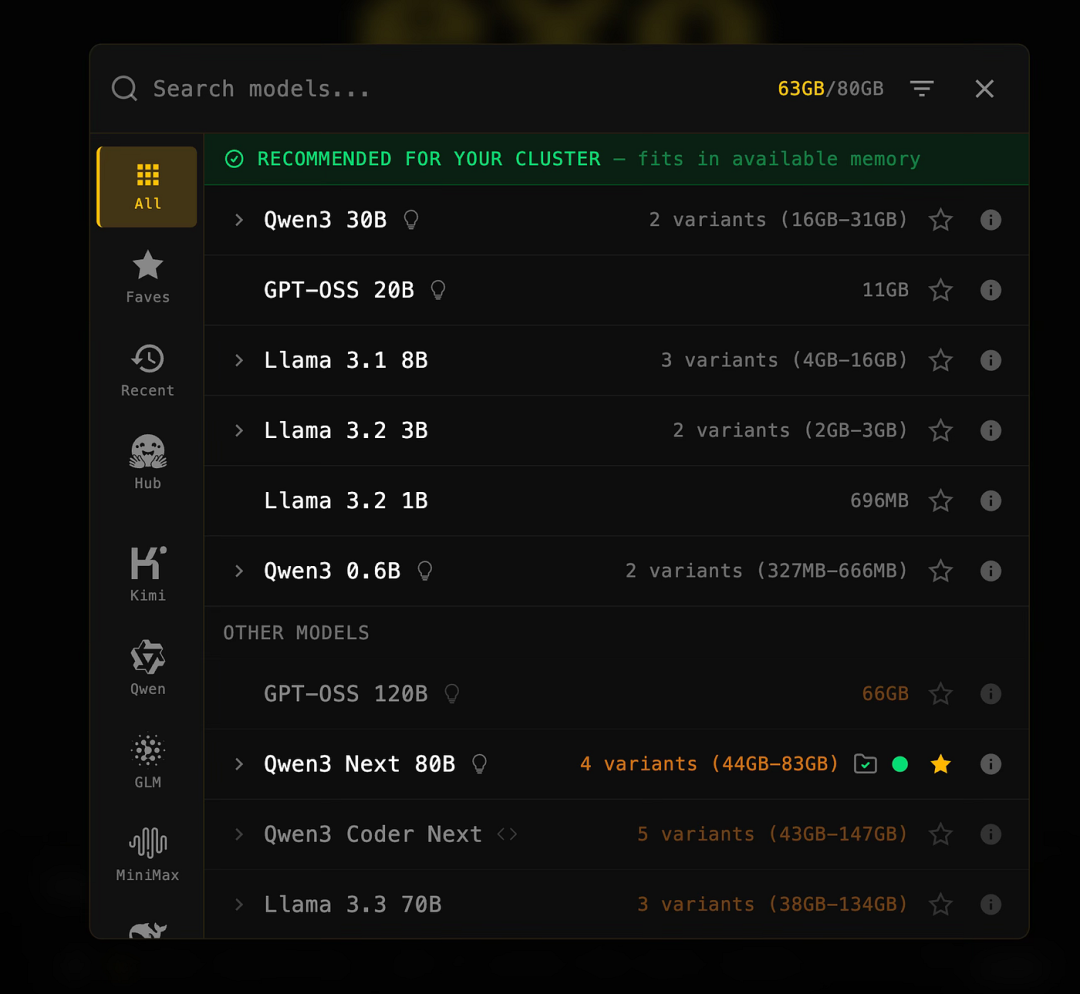
内置网页控制面板提供实时集群拓扑视图:
- 每个节点显示 CPU 使用率、温度、功耗、内存利用率
- 显示哪个设备处理模型的哪一部分
- 显示可组合的 RAM 和可运行的模型
资源分配
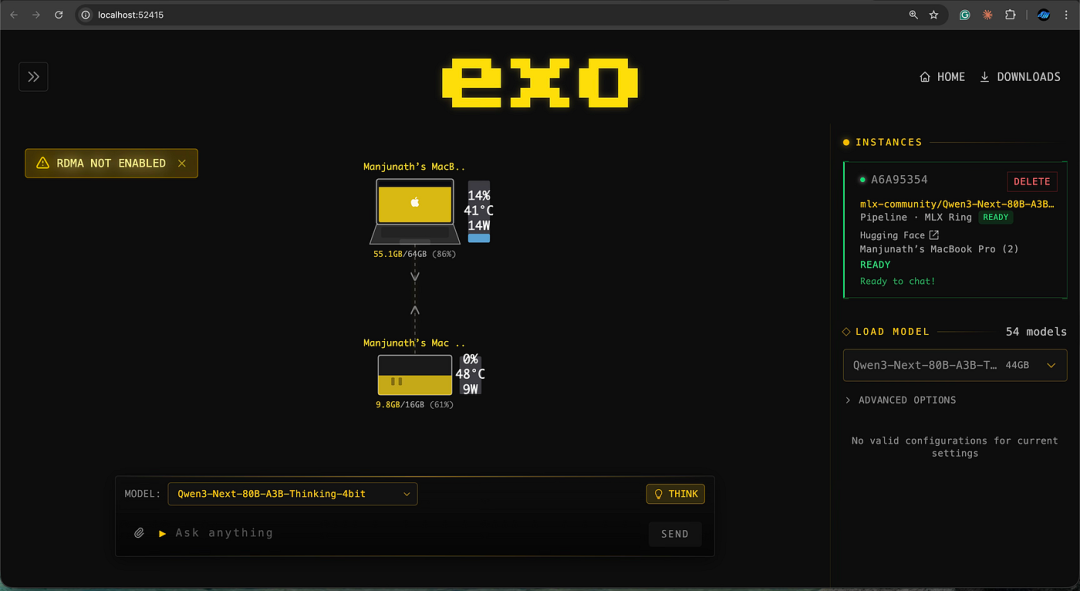
模型根据每台机器的 RAM 分层:
- Mac Mini CPU 飙升到 97%,温度 86°C,功耗 82W
- MacBook Pro 稳定在 8–13%
exo 足够智能,根据可用资源自动分配工作负载。
THINK 模式
仪表板中的 THINK 模式启用思维链推理,生成后可展开或折叠查看。
API 兼容性
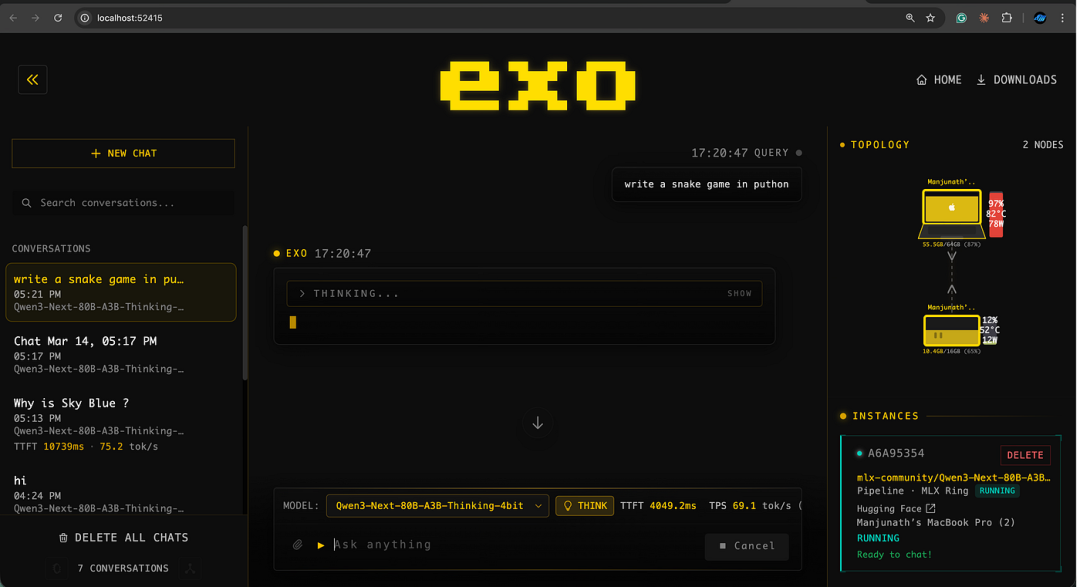
exo 在 http://localhost:52415/v1 暴露完全兼容 OpenAI 的 REST API。
快速示例
curl -N -X POST http://localhost:52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "mlx-community/Qwen3-Next-80B-A3B-Thinking-4bit",
"messages": [{"role": "user", "content": "What is sky blue?"}],
"stream": false
}'兼容工具:
- Agentic AI 应用
- LangChain
- LlamaIndex
- OpenAI SDK 客户端
Thunderbolt 5 RDMA
如果你有支持 Thunderbolt 5 的 M4 Pro 或 M4 Max 硬件,exo 支持 RDMA(远程直接内存访问)。
这是 macOS 26.2 中新增的功能,据报告可将节点间延迟降低高达 99%,达到与数据中心互联相当的性能。
⚠️ 作者的设置使用 WiFi,未启用 RDMA。但 Jeff Geerling 的 4 × M3 Ultra Mac Studio 集群基准测试显示 Qwen3–235B 以生产级速度运行。
性能实测数据
| 测试查询 | TTFT | TPS |
|---|---|---|
| "为什么天空是蓝色的?" | 10,739 ms | 75.2 tokens/秒 |
| "用 Python 编写贪吃蛇游戏" | 4,049 ms | 69.1 tokens/秒 |
| 常规推理 | - | 68–75 tokens/秒 |
💡 THINK 模式下 TTFT 会增加,但输出质量明显更强。
对于完全在本地硬件上运行、零云成本的 80B 参数推理模型,这些数字令人印象深刻。
总结
关键要点
| 要点 | 说明 |
|---|---|
| 入门门槛低 | 主要在 Mac 上,原生应用一键安装 |
| 上限高 | 可运行 80B 甚至更大模型 |
| 实用性强 | OpenAI API 兼容,无缝对接现有工具 |
| 分布式推理 | WiFi 网络两台笔记本即可 |
适用场景
- 构建 agentic AI system
- 运行本地实验
- 探索硬件协同工作
🔗 相关链接
- GitHub: exo-explore/exo
- MLX: ml-explore/mlx
- MLX 分布式文档: distributed.html
📘 本文来自微信公众号「楠楠自瑜」,由 AiTimes 智能时代整理发布
AiTimes 智能时代 © 2026